
Python程序设计基础(七)
文件和数据格式化
文件的使用
文件是存储在辅助存储器上的一组数据序列, 可以包含任何数据内容。
概念上, 文件是数据的集合和抽象。
文件包括文本文件和二进制文件两种类型。
文件的类型
文本文件一般由单一特定编码的字符组成, 如UTF-8编码, 内容容易统一展示和阅读。大部分文本文件都可以通过文本编辑软件或文字处理软件创建、修改和阅读。
由于文本文件存在编码, 所以, 它也可以被看作是存储在磁盘上的长字符串, 如一个txt格式的文本文件。
二进制文件直接由比特 0 和比特 1 组成, 没有统一的字符编码, 文件内部数据的组织格式与文件用途有关。二进制文件是信息按照非字符但有特定格式形成的文件, 如png格式的图片文件、aⅵ格式的视频文件。
二进制文件和文本文件最主要的区别在于是否有统一的字符编码。二进制文件由于没有统一的字符编码, 只能当作字节流, 而不能看作是字符串。
无论文件创建为文本文件或者二进制文件, 都可以用“文本文件方式”和“二进制文件方式打开, 但打开后的操作不同。
新建一个a.txt的文件,输入内容 “你好”,然后用Python编写代码开启
注意:文本文件和Python程序文件要在同一个目录内
1 | #open()为打开文件,rt分别为:r - 只读,t - 文本文件方式打开 |
当然,文本文件也可以用二进制文件方式打开
1 | #open()为打开文件,rt分别为:r - 只读,b - 二进制文件方式打开 |
采用文本文件方式读入文件, 文件经过编码形成字符串, 打印出有含义的字符; 采用二进制文件方式打开文件, 文件被解析为字节流。由于存在编码, 字符串中的一个字符由多个字节表示。
文件的打开与关闭
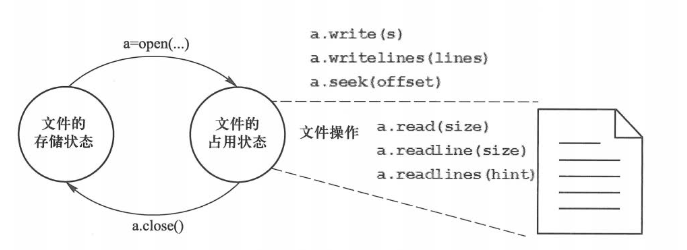
Python通过open()函数打开一个文件, 并返回一个操作这个文件的变量
1 | <变量名> = open(<文件路径及文件名>,<打开模式>) |
open函数有两个参数:文件名和打开模式。文件名可以是文件的实际名字, 也可以是包含完整路径的名字。打开模式用于控制使用何种方式打开文件, open()函数提供7种基本的打开模式。

常用组合:
1 | #1.以文本文件方式只读打开一个文件,读入后不能对文件进行修改。 |
当我们需要使用完整路径打开文件时
1 | path = "C:\\Users\\JM\\Desktop\\" |
注意:因为\是字符串中的转义符,所以表示路径时,使用\\或/代替\)
文件的读取
| 方法 | 含义 |
|---|---|
| f.read( size=-1) | 从文件中读入整个文件内容。参数可选,如果给出,读入前 size 长度的字符串或字节流 |
| f.readline(size =-1) | 从文件中读入一行内容。参数可选,如果给出,读人该行前 size 长度的字符串或字节流 |
| f.readlines( hint=-1) | 从文件中读入所有行,以每行为元素形成一个列表。参数可选,如果给出,读入 hint行 |
| f.seek( offset) | 改变当前文件操作指针的位置,offset 的值:0为文件开头:2为文件结尾 |
如果文件以文本文件方式打开, 则读入字符串; 如果文件以二进制文件方式打开, 则读字节流。
如果文件不大, 可以一次性将文件内容读入,保存到程序内部变量中。 f.read()是最常用的次性读入文件的函数, 其结果是一个字符串。
1 | f = open("a.txt","r") |
f.readlines()也是一次性读入文件的函数, 其结果是一个列表, 每个元素是文件的一行。
1 | f = open("a.txt","r") |
在文件打开后, 对文件的读写有一个读取指针, 当从文件中读入内容后, 读取指针将向前进, 再次读取的内容将从指针的新位置开始。
1 | f = open("a.txt","r") |
我们可以发现,最后一次读取返回了一个空的列表,这是因为第一次f.read()已经读取了文件全部内容,读取指针在文件末尾,再次调用f.readlines()时,指针已经无法再次向后读取内容,所以,结果为空。
f.seek()方法能够移动读取指针的位置, seek(0)将读取指针移动到文件开头, feek(2)将读取指针移动到文件结尾。
1 | f = open("a.txt","r") |
遍历循环逐行打印文件
1 | f = open("a.txt","r") |
两行文字输出之间有一个个空行, 这是因为原文第一行后有一个换行符,再使用 print输出时默认增加一个换行。
文件的写入
| 方法 | 含义 |
|---|---|
| f.write( s) | 向文件写入一个字符串或字节流 |
| f.writelines( lines) | 将一个元素为字符串的列表整体写入文件 |
f.write(s)向文件写入字符串s, 每次写入后, 将会记录一个写入指针。该方法可以反复调用, 在写入指针后分批写入内容, 直至文件被关闭。
1 | f = open("a.txt","w") |
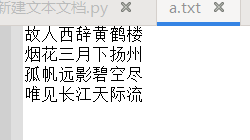
f.writelines( lines)直接将列表类型的各元素连接起来写入文件f
1 | ls = ['故人西辞黄鹤楼,烟花三月下扬州。\n', '孤帆远影碧空尽,唯见长江天际流。'] |
数据组织的维度
一组数据在被计算机处理前需要进行一定的组织, 表明数据之间的基本关系和逻辑, 进而形成“数据的维度”。根据数据的关系不同, 数据组织可以分为:一维数据、二维数据和高维数据。
一维数据的定义
一维数据由对等关系的有序或无序数据构成,采用线性方式组织,对应于数学中数组的概念。
例如,中国的直辖市列表即可表示为一维数据。一维数据具有线性特点。
一维数据十分常见,任何表现为序列或集合的内容都可以看作是一维数据。
二维数据的定义
二维数据, 也称表格数据, 由关联关系数据构成, 采用二维表格方式组织, 对应于数学中的矩阵。
常见的表格都属于二维数据。
高维数据的定义
高维数据由键值对类型的数据构成, 采用对象方式组织, 可以多层嵌套。
高维数据在Web系统中十分常用, 作为当今 Internet组织内容的主要方式,高维数据衍生出HTML、XML、JSON等具体数据组织的语法结构
一维数据
一维数据是最简单的数据组织类型。由于是线性结构, 在 Python语言中主要采用列表形式表示。例如, 中国的直辖市数据可以采用一个列表变量表示。
1 | ls = ["北京","上海","天津","重庆"] |
一维数据的存储
一维数据的文件存储有多种方式, 总体思路是采用特殊字符分隔各数据。
常用的存储方法:
空格分隔元素
逗号分隔元素
换行分隔元素
其他特殊符号分隔元素(比如:分号)
这4种方法中, 逗号分隔的存储格式被称为CSV格式( Comma- Separated values,逗号分隔值), 它是一种通用的、相对简单的文件格式, 在商业和科学上广泛应用, 大部分编辑器都支持直接读入或保存文件为CSV格式, 如 Windows平台上的记事本或微软 Office Excel等。存储的文件般采用csv为扩展名。
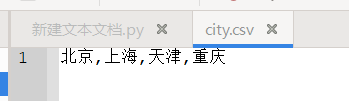
一维数据保存成CSV格式后, 各元素间采用逗号分隔, 形成一行。从 Python表示到数据存储,需要将列表对象输出为CSV格式以及将CSV格式读入成列表对象。
1 | ls = ["北京","上海","天津","重庆"] |
列表对象输出为CSV格式文件, 采用字符串的join()方法最为方便。
一维数据的处理
对一维数据进行处理首先需要从CSV格式文件读入一维数据, 并将其表示为列表对象。需要注意,从CSV文件中获得内容时, 最后一个元素后面包含了一个换行符。
对于数据的表达和使用来说, 这个换行符是多余的, 需要采用字符串的 strip()方法去掉数据尾部的换行符,进一步步使用 split()方法以逗号进行分割。
1 | f = open("city.csv","r") |
二维数据
二维数据由多个一维数据构成, 可以看作是一维数据的组合形式。
因此,二维数据可以采用二维列表来表示, 即列表的每个元素对应二维数据的一行, 这个元素本身也是列表类型, 其内部各元素对应这行中的各列值。
1 | ls = [ |
二维数据的存储
二维数据由一维数据组成,用CSV格式文件存储。CSV文件的每一行是一维数据, 整个CSV文件是一个二维数据。
二维数据存储为CSV格式,需要将二维列表对象写人CSV格式文件以及将CSV格式读入成二维列表对象。
二维列表对象输出为CSV格式文件方法如下(采用遍历循环和字符串的 join()方法相结合)。
1 | ls = [ |
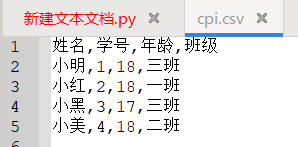
二维数据的处理
对二维数据进行处理首先需要从CSV格式文件读入二维数据, 并将其表示为二维列表对象。
1 | f = open("cpi.csv","r") |
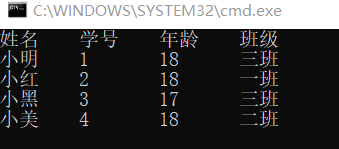
对二维数组进行格式化输出,打印成表格
1 | f = open("cpi.csv","r") |
 wechat
wechat alipay
alipay









