
Python程序设计基础(三)
基本数据类型
数字类型
Python语言提供3种数字类型:整数类型、浮点数类型和复数类型,分别对应数学中的整数、实数和复数。
例如,1010是整数类型,10.10是浮点数类型,10+10j是复数类型。
整数类型
整数类型与数学中整数的概念一致,理论上的取值范围是[-∞,+∞],实际上,只要计算机内存能够存储, Python程序可以使用任意大小的整数。
一般认为整数类型没有取值范围限制整数类型有4种进制表示:十进制、二进制、八进制和十六进制。

不同进制的整数之间可以直接运算或比较。
程序无论采用何种进制表达数据,计算机内部都以相同的二进制格式存储数值,为易于理解,进制之间的运算结果默认以十进制方式显示。
1 | print(0b1010+1010) #1020 |
浮点数类型
浮点数类型与数学中实数的概念一致,表示带有小数的数值。
Python语言中的浮点数类型必须带有小数部分,小数部分可以是0。
例如:1010是整数,1010.0是浮点数。
浮点数有两种表示方法:十进制形式的一般表示和科学计数法表示。
如1010.0,-1010.0,1.01e3,-1.01E-3
科学计数法种使用字母e或者E作为幂的符号
如:1.01e3
即1.01*10^3 = 1010.0
浮点数类型的数值范围和小数精度受不同计算机系统的限制,一般来说,浮点数的取值范围在-1.79×10~0到1.79×100之间,浮点数之间的区分精度约为2.22×106。
对于除高精度科学计算外的绝大部分运算来说,浮点数类型的数值范围和小数精度足够“可靠”,一般认为浮点数类型没有范围限制,运算结果准确。
1 | print(123.456789+987.654321) #1111.11111 |
复数类型
复数类型表示数学中的复数。复数有一个基本单位元素j,它被定义为j=√-1,叫作“虚数单位”。含有虚数单位的数被称为复数。
如:11.3+4j,-5.6+7j
Python语言中,复数可以看作是二元有序实数对(a,b),表示a+bj,其中,a是实数部分,简称实部,b是虚数部分,简称虚部。
虚数部分通过后缀“J”或者“j”来表示。需要注意,当b为1时,1不能省略,即1表示复数,而j则表示 Python程序中的一个变量。
复数类型中实部和虚部都是浮点类型,对于复数z,可以用z.real和z.imag分别获得它的实数部分和虚数部分。示例如下。
1 | #获得(1.23e4+5.67e4j)的实数部分,即1.23e4 |
数字类型的运算
数值运算操作符
Python提供了9个基本的数值运算操作符

加减乘除就不多说了,和数学一致
数值运算可能改变结果的数据类型,类型的改变与运算符有关
- 整数和浮点数混合运算,输出结果是浮点数;
- 整数之间运算,产生结果类型与操作符相关,除法运算(/)的结果是浮点数
- 整数或浮点数与复数运算,输出结果是复数。
1 | print(1010/10) #101.0 |
所有二元运算操作符都可以与赋值符号=相连,形成增强赋值操作符(+=、-=、*=、/=、∥/=、%=、**=)。
1 | x = 2 |
数值运算函数
函数不同于操作符,其表现为对参数的特定运算。
Python解释器自身提供了一些预装函数称为“内置函数”。

abs()函数
abs(x)用于计算整数或浮点数x的绝对值,结果为非负数值。
该函数也可以计算复数的绝对值。复数以实部和虚部为二维坐标系的横纵坐标值,其绝对值是坐标点到原点的距离,例如,复数z=a+b,其绝对值abs(x)为√a^2+b^2。由于实部和虚部都是浮点数,所以复数的绝对值也是浮点数。
1 | print(abs(-20)) #20 |
divmod()函数
divmod(x,y)函数用来计算x和y的除余结果,返回两个值,分别是:x与y的整数除,即x//y,以及x与y的余数,即x%y。
返回的两个值组成了一个元组类型,即小括号包含的两个元素。可以通过赋值方式将结果同时反馈给两个变量。
1 | print(divmod(100,9)) #(11, 1) |
pow()函数
pow(x,y)函数用来计算x的y次幂,与x**y相同。
pow(x,y,x)则用来计算x%z,模运算与幂运算同时进行,速度更快。
1 | print(pow(5,2)) #25 |
round()函数
round()对整数或浮点数x进行四舍五入运算。
round(x,d)对浮点数x进行带有d位小数的四舍五入运算。需要注意,“四舍五入”只是一个约定说法,并非所有的5都会被进位。
对于x.5,当x为偶数时,x.5并不进位,如 round(0.5)值为0;当x为奇数时,x.5进位,如 round(1.5)值为2。这是由于x.5严格处于两个整数之间,从“平等价值”角度考虑,将所有x.5情况分为两类,采用“奇进偶不进”的方式运算。
但对于x.50001这种非对称情况,则按照进位法则处理。
1 | print(round(1.4)) #1 |
min()和max()函数
min()和max()可以对任意多个数值进行最小值或最大值比较,并输出结果。
1 | print(min(1,2,3,4,6,8,0,12)) #0 |
数值比较运算
Python提供了6个比较运算符

1 | print(12>5) #True |
当涉及复数类型的比较运算受限,只能判断是否相等,即使用==和!=符号,而其他判断大小的比较符号不能使用,否则会报错。
字符串类型及格式化
字符串符号
字符串是字符的序列表示,根据字符串的内容多少分为单行字符串和多行字符串。
单行字符串可以由一对单引号''或双引号""作为边界来表示,单引号和双引号作用相同。
当使用单引号时,双引号可以作为字符串的一部分;当使用双引号时,单引号可以作为字符串的一部分。
多行字符串可以由一对三单引号'''或三双引号"""作为边界来表示
1 | print("字符串") |
多行字符串用于大段文本的情况,一般采用变量表示。
1 | s="""第一行 |
反斜杠字符(\)是一个特殊字符,在 Python字符串中表示“转义”,即该字符与后面相邻的个字符共同组成了新的含义。
如:\n表示换行、\\表示反斜杠、\‘表示单引号、\“表示双引号、\t表示制表符(Tab)等。
如果在字符串中既需要出现单引号又需要出现双引号,则需使用转义符。
1 | print("这里\n换行") |
字符串索引
对字符串中某个字符的检索被称为索引。
<字符串或字符串变量>[序号]
字符串包括两种序号体系:正向递增序号和反向递减序号(前面一章有提到)
1 | print("Hello World"[1]) #e |
字符串切片
对字符串中某个子串或区间的检索称为切片。
<字符串或字符串变量>[N:M]
切片获取字符串从N到M(不包含M)的子字符串
其中,N和M为字符串的索引序号,可混合使用正向递增序号和反向递减序号。
切片要求N和M都在字符串的索引区间,如果N大于等于M,则返回空字符串。如果N缺失,则默认将N设为0;如果M缺失,则默认表示到字符串结尾。
1 | print("Hello World"[2:4]) #ll |
字符串切片还有一种高级用法
<字符串或字符串变量>[N:M:K]
该方法获取字符串从N到M(不包含M)、以K为步长的子字符串
其中,N和M为字符串的索引序号,可以混合使用正向递增序号和反向递减序号,K为整数。特别是当K为负数时,将返回从M到N(不包含N)的反向字符子串。
1 | print("Hello World"[0:8:2]) #HloW |
字符串基本格式化
在字符串中整合变量时需要使用字符串的格式化方法。
字符串格式化用于解决字符串和变量同时输出时的格式安排问题。
<模板字符串>format(<逗号分隔的参数>)
如果模板字符串有多个槽,且槽内没有指定序号,则按照槽出现的顺序分别对应 format()方法中的不同参数。
1 | print("{}好,{}好,{}好".format("你","我","大家")) |
我们也可以通过指定参数的方式,使用format(),参数从0开始编号
1 | print("{1}爱{0}".format("你","我")) |
如果要在<模板字符串>中输出大括号{},就需要使用{{}}
1 | print("{{{1}爱{0}}}".format("你","我")) #{我爱你} |
字符串的格式控制
format()方法的槽除了包括参数序号,还可以包括格式控制信息
{<参数序号>:<格式控制标记>}
其中,格式控制标记用来控制参数显示时的格式
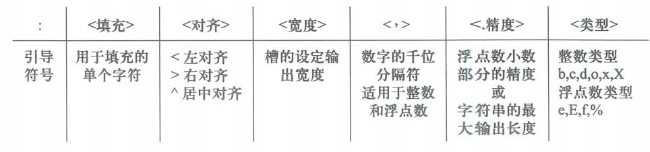
格式控制标记包括:<填充><对齐><宽度><,><精度><类型>6个字段,由引导符号:作为引导标记,这些字段都是可选的,可以组合使用。
这6个格式控制标记可以分为两组。
第一组是<填充><对齐>和<宽度>,它们是相关字段,主要用于对显示格式的规范。
宽度指当前槽的设定输出字符宽度,如果该槽参数实际值比宽度设定值大,则使用参数实际长度。如果该值的实际位数小于指定宽度,则按照对齐指定方式在宽度内对齐,默认以空格字符补充。
对齐字段分别使用<、>和^三个符号表示左对齐、右对齐和居中对齐。(默认为左对齐)
填充字段可以修改默认填充字符,填充字符只能有一个。
1 | s = "你好" |
当然,<格式控制标记>也可以用变量来表示
1 | s = "你好" |
第二组是<,><.精度>和<类型>,主要用于对数值本身的规范。
其中,逗号,用于显示数字类型的千位分隔符。
1 | print("1{:-^15,}1".format(123456)) #1----123,456----1 |
<精度>由小数点.开头。
对于浮点数,精度表示小数部分输出的有效位数。
对于字符串,精度表示输出的最大长度。此时,小数点可以理解为对数值的有效截断;如果小数点保留长度超过应输出长度,以应输出长度为准。
1 | print("1{:-^15.2f}1".format(12.3456)) #1-----12.35-----1 |
<类型>表示输出整数和浮点数类型的格式规则。
对于整数类型,输出格式包括如下6种
- b:输出整数的二进制方式;
- c:输出整数对应的 Unicode字符;
- d:输出整数的十进制方式;
- o:输出整数的八进制方式;
- x:输出整数的小写十六进制方式;
- X:输出整数的大写十六进制方式。
1 | print("{0:b},{0:c},{0:d},{0:o},{0:x},{0:X}".format(43)) #101011,+,43,53,2b,2B |
对于浮点数类型,输出格式包括如下4种
e:输出浮点数对应的小写字母e的指数形式
E:输出浮点数对应的大写字母E的指数形式;
f:输出浮点数的标准浮点形式;
%:输出浮点数的百分比形式。
注:浮点数输出时尽量使用<精度>表示小数部分的输出长度,有助于更好地控制输出格式.
1 | print("{0:e},{0:E},{0:f},{0:%}".format(3.14)) #3.140000e+00,3.140000E+00,3.140000,314.000000% |
字符串操作符
针对字符串, Python语言提供了3个基本操作符
| 操作符 | 描述 |
|---|---|
| + | x+y,连接两个字符串x与y |
| * | x*n或n*x,复制n次字符串x |
| in | x in s,如果x是s的子串,返回True,否则返回 False |
1 | print("hello"+"world") #helloworld |
字符串处理函数
Python语言提供了一些对字符串进行处理的内置函数

len()函数
len(x)返回字符串x的长度,以 Unicode字符为计数基础,因此,中英文字符及标点字符等都是1个长度单位。
1 | print(len("你好")) #2 |
str()函数
str(x)返回x的字符串形式,其中,x是数字类型或其他类型。
1 | print(str("你好")) |
chr()和ord()函数
chr(x)和ord(x)函数用于在单字符和 Unicode编码值之间进行转换。
chr(x)函数返回Uni-e编码对应的字符,ord(x)函数返回单字符x对应的 Unicode编码。
1 | print(chr(100)) |
hex()和oct()函数
hex(x)和oct(x)函数分别返回整数x对应十六进制和八进制值的字符串形式,字符串以小写形式表示。
1 | print(hex(1010)) |
字符串处理方法
“方法”是程序设计中的一个专有名词,属于面向对象程序设计领域。
在 Python解释器内部,所有数据类型都采用面向对象方式实现,因此,大部分数据类型都有一些处理方法。
方法也是一个函数,只是调用方式不同。函数采用func(x)方式调用,而方法则采用\<a>.func(x)形式调用,即A.B()形式。方法仅作用于前导对象<a>。
| 方法 | 描述 |
|---|---|
| str.lower() | 返回字符串str的副本,全部字符小写 |
| str.upper() | 返回字符串str的副本,全部字符大写 |
| str.split ( sep = None ) | 返回一个列表,由str根据sep被分割的部分构成,省略sep默认以空格分隔 |
| str.count ( sub ) | 返回sub子串出现的次数 |
| str.replace( old , new ) | 返回字符串st的副本,所有old子串被替换为new |
| str.center ( width , fillchar ) | 字符串居中函数, fillchar参数可选 |
| str.strip ( chars ) | 从字符串str中去掉在其左侧和右侧 chars中列出的字符 |
| str.join ( iter ) | 将iter变量的每一个元素后增加一个str字符串 |
str.lower()和 str.upper()函数
str.lower()和 str.upper()是一对方法,能够将字符串的英文字符变成小写或大写。
1 | print("Hello".lower()) #hello |
str.split()函数
str. split(sep)是一个十分常用的字符串处理方法,它能够根据sep分隔字符串 str。sep不是必需的,默认采用空格分隔,sep可以是单个字符,也可以是一个字符串。分割后的内容以列表类型返回。
1 | s = "Hello World Hello World" |
str.count()函数
str.count(sub)方法返回字符串str中出现sub的次数,sub是一个字符串。
1 | s = "Hello World Hello World" |
str.replace()函数
str.replace(old,new)方法将字符串str中出现的old字符串替换为new字符串,old和new的长度可以不同。
1 | s = "Hello World Hello World" |
str.center()函数
str.center(width, fillchar)方法返回长度为 width的字符串。其中,str处于新字符串中心位置,两侧新增字符采用 fillchar填充,当 width小于字符串长度时,返回str; fillcher是单个字符
1 | print("Hello".center(15,"=")) #=====Hello===== |
str.strip()函数
str.strip(chars)从字符串str中去掉在其左侧和右侧 chars中列出的字符。 chars是一个字符串,其中出现的每个字符都会被去掉。
1 | s = "===Hello===" |
str.join()函数
str.join(iter)中iter是一个具备迭代性质的变量,例如列表变量或字符串变量。该方法将str字符串插入iter变量的元素之间,形成新的字符串。简单地说, join方法能够在一组数据中增加分隔字符。
1 | print(" ".join("hello")) #h e l l o |
字符串的比较运算
与数值比较运算一样,字符串也可以进行比较运算,有6种操作,即大于(>)、大于等于(>=)、小于(<)、小于等于(<=)、等于(==)、不等于(!=)。两个字符串比较采用从左向右依次比较字符的方式,根据字符对应 Unicode编码值大小决定字符串大小关系。
1 | print("123"=="123") #True |
“h” > “Hello”,字符”h”比”H”的 Unicode编码值大,所以结果为True,此时,后续字符并不需要比较。
类型的判断与类型的转换
类型判断
Python语言提供type(x)函数对变量x进行类型判断,适用于任何数据类型
1 | print(type(123)) #<class 'int'> |
类型转换
数字运算的输出结果类型可能与输入数字的类型不同,例如,两个整数采用运算符/的除法将可能输出浮点数结果。此外,通过内置的数字类型转换函数可以显式地在数字类型之间进行转换

浮点数转换为整数类型时,小数部分会被舍弃掉(不使用四舍五人)。整数转换成浮点数类型时,会额外增加小数部分。二进制、八进制、十六进制整数转换为字符串类型时统一表示为十进制字符串形式。
1 | print(int(10.56)) #10 |
真假无值与逻辑运算
真假值
True和 False是 Python的保留字,表达相对立的“真假”二元数值。很多资料将True和 False称为布尔(bool)类型,严格说,它们只是值,属于数字类型。其中,True表示与1相等的值, False表示与0相等的值,可以用数学比较运算检查一下。
1 | print(0.0==False) #True |
无值
None是 Python的保留字,表达无、没有、空等含义。
None不是 False,不表示0,不表示空字符串,不对应任何数值。
1 | print(0==None) #False |
逻辑运算

“与操作”是二元操作,当x和y都是True时,结果为True;当x或y其一为 False时,结果为False。
与操作也可以在True、 False及数字之间进行逻辑运算,其中,只有0值表示 False,其他值均表示True。
1 | print(True and False) #False |
“或操作”是二元操作,当x和y都是 False时,结果为False;当x或y其一为True时,结果为True。
或操作也可以在True、 False及数字之间进行逻辑运算。多个或操作也可以组合使用。
1 | print(True or False) #True |
“非操作”是一元操作,对x进行取反,即当x为True时,结果为 False,当x为 False时,结果为True。
1 | print(not False) #True |
Python实例
凯撒密码
恺撒密码是古罗马恺撒大帝用来对军事情报进行加密的算法,它采用了替换方法将信息中的每一个英文字符循环替换为字母表序列中该字符后面的第三个字符,即循环右移3位
原文: ABCDEFGHIJKLMNOPQRSTUVWXYZ
密文: DEFGHIJKLMNOPORSTUVWXYZABC
加密:
1 | test = input("请输入明文:") |
解密:
1 | test = input("请输入密文:") |
而基本汉字的 Unicode编码范围是0x4E00~0x9FA5,共20902字。
可以采用简化的 Unicode码左移3位方式实现加密。
中文加密:
1 | test = input("请输入明文:") |
中文解密:
1 | test = input("请输入密文:") |
 wechat
wechat alipay
alipay








